
Overview
Note: it was pointed out to us by a reader that this article doesn't properly address content filtering with HTTPS. Therefore, we're in the process of updating this article.
The Squid caching proxy is an excellent, long established open source project with an active mail list. Aside from the core proxy and cache functionality, Squid is also great for managing, filtering, & analyzing HTTP and HTTPS accesses. An example of this is using a content filter to either rewrite or redirect URLs, and a typical application for this is blocking tracking sites and objectionable content, such as ads and porn. This article reviews writing a simple content filter in Python and testing / debugging it.
Note that ad blockers have become popular in browsers for good reason, but if you want complete control in a unified manner across all browsers / clients, we suggest implementing a centralized content filter.
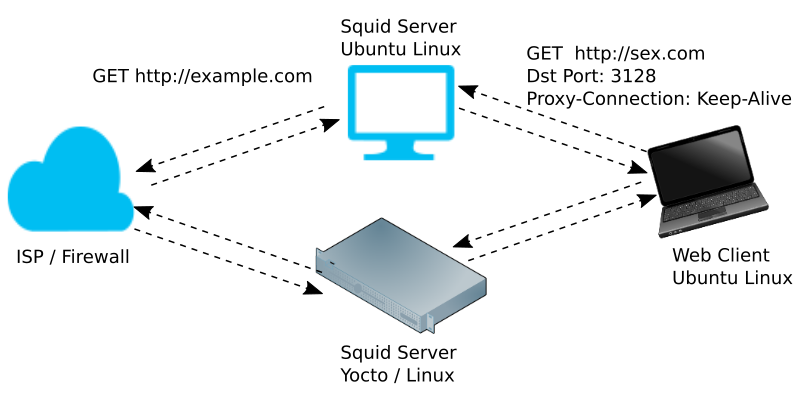
For development and testing, we set up two squid servers:
- A PC running Ubuntu Linux 18.04 using Squid built from source as described in this article.
- An embedded Linux system running a Yocto-built distribution with Linux (similar to what we use to protect our own network). Note that the most recent Squid recipe can be found on the OpenEmbedded cgit site.
Each Squid server is positioned between our ISP firewall / router and our test client. Our test client is a second PC running Ubuntu Linux 18.04, and we make use of the command line wget utility to test our squid servers.
Server Configuration
On Ubuntu 18.04, we are running Squid version 4 built from source, as described in this article. On Yocto, we are running version 3.5.27 built from a recent meta-openembeded recipe.
Our Ubuntu shell:
$ squid -v Squid Cache: Version 4.6-VCS Service Name: squid configure options: '--prefix=/opt/squid' '--with-default-user=squid' '--enable-ssl' '--disable-inlined' '--disable-optimizations' '--enable-arp-acl' '--disable-wccp' '--disable-wccp2' '--disable-htcp' '--enable-delay-pools' '--enable-linux-netfilter' ...
Our Yocto shell:
# squid -v # our Yocto shell
Squid Cache: Version 3.5.27
Service Name: squid
Ubuntu linux
configure options: '--build=x86_64-linux-gnu' '--prefix=/usr' '--includedir=${prefix}/include'
'--mandir=${prefix}/share/man' '--infodir=${prefix}/share/info' '--sysconfdir=/etc' '--localstatedir=/var'
'--libexecdir=${prefix}/lib/squid3' '--srcdir=.' '--disable-maintainer-mode' '--disable-dependency-tracking'
...
On Yocto, we make a few tweaks to the server. For example, make sure we can view our Squid logs at /var/log/squid, and the owner is "squid":
# mkdir -p /var/log/squid # chown -R squid:squid /var/log/squid
We also make configuration tweaks on Ubuntu as described in this article.
On both servers, we need to set up an access control list (acl), so we can use a remote client:
acl localnet src 192.168.3.0/24 http_access allow localnet
Client Configuration
For our testing on the client, we temporarily configure use of the proxy in a shell (e.g., gnome-terminal). Before doing this, make sure wget is working properly.
$ wget http://example.com ... Saving to: ‘index.html’ ... $ export http_proxy=<server ip address>:3128
Basic Squid Test
As a basic sanity test, we'll run Squid on each server without our rewriter (content filter) enabled and run a few wget requests on our client.
$ wget cnn.com $ wget foxnews.com
View the contents of the files that should have been returned (e..g, index.html). You should see HTML content in the files from the sites you requested. If it's not working properly, view the squid cache.log file for hints on what might be wrong and feel free to post any issues below.
While you're testing, keep in mind the following useful squid commands (On Ubuntu, preface each with a sudo if you installed squid using apt):
squid # start the server squid -k reconfigure # restart the server each time you tweak your redirector squid -k interrupt # bring squid to a stop squid -k check # is it running?
For additional help configuring Squid, Kulbir Saini's Squid Proxy Server 3.1 is an excellent reference, even for Squid version 4.
Testing the Custom Content Filter
Now it's time to enable our rewriter and test it out. The relevant excerpt of our squid.conf file is shown below. If you're unfamiliar with these settings, then refer to the references provided below.
url_rewrite_extras "%>a %>rm %un" url_rewrite_children 3 startup=0 idle=1 concurrency=10 url_rewrite_program /build/squid_redirect/squid-redirect.py
Refer to the source / python script provided below and move it to the location specified in your squid.conf file for the url_rewrite_program directive. Also, refer to the reference for this directive for an understanding of the communication between the Squid server and the redirector helper.
After making changes to squid.conf or your Python redirect script squid-redirect.py, don't forget to restart your server and check that it's running:
$ ./squid -k reconfigure $ ps -e | grep squid 24122 ? 00:00:00 squid 24124 ? 00:00:00 squid
Our redirector example will perform:
- a rewrite if "sex" is in the URL (not a good idea, e.g., would block http://oasisunisex.com/)
- a redirect if the URL suffix is ".xxx".
Let's try it:
$ wget sex.com
...
Proxy request sent, awaiting response... 200 OK
Length: 1270 (1.2K) [text/html]
Saving to: ‘index.html’
...
$ grep example index.html
<p>This domain is established to be used for illustrative examples in documents. You may use this
domain in examples without prior coordination or asking for permission.</p>
...
Please keep in mind that this is just example / demo code to show how things work. There are various complete content filters available for Squid, but it's also very enticing to write your own if you enjoy working with Python, like we do.
Debugging the Custom Content Filter
Notice that the content filter script makes use of Python's logging facility. On our Ubuntu 18.04 system, we find the squid-redirect.log file under /opt/squid/var/cache/squid ( /var/spool/squid if you installed with apt). In it, we find lines such as:
DEBUG:root:2019-04-02 01:13:22: 1 http://sex.com/ 192.168.3.10 GET -
The "http://sex.xxx/ 192.168.3.10 GET -" string is what was passed to our content filter script by Squid.
For development and testing, the squid-redirect.py file can be executed in a shell without running Squid. Open up a new shell on the server in the folder where squid-redirect.py is located, execute squid-redirect.py, and start passing it requests using stdin (type them in yourself):
$ cd /build/squid_redirect/ $ python3 squid-redirect.py 0 http://sex.xxx/ 127.0.0.1 GET - 0 OK rewrite-url=https://example.com
When executing this script locally in your shell, Python logging will write the squid-redirect.log file to the same local directory.
#!/usr/bin/env python3 """ Copyright 2018, 2019 Mind Chasers Inc, file: squid-redirect.py Demo code. No warranty of any kind. Use at your own risk """ VERSION=0.2 import re import sys import logging from datetime import datetime logging.basicConfig(filename='squid-redirect.log',level=logging.DEBUG) xxx = re.compile('\.xxx?/$') def main(): """ keep looping and processing requests request format is based on url_rewrite_extras "%>a %>rm %un" """ request = sys.stdin.readline() while request: [ch_id,url,ipaddr,method,user]=request.split() logging.debug(datetime.now().strftime('%Y-%m-%d %H:%M:%S') + ': ' + request +'\n') response = ch_id + ' OK' if 'sex' in url: response += ' rewrite-url=https://example.com' elif xxx.search(url): response += ' status=301 url=https://example.com' response += '\n' sys.stdout.write(response) sys.stdout.flush() request = sys.stdin.readline() if __name__ == '__main__': main()
References
- Squid configuration directive: url_rewrite_program
- Squid configuration directive: url_rewrite_children
- Squid configuration directive: url_rewrite_extras




Date: May 15, 2024
Author: alejcbox
Comment: